
「あの展覧会混んでる?」は展覧会の混雑状況をビッグデータの解析から明らかにしようとする世界で初めてのサービスです。
美術鑑賞が趣味のhanachanが独自に開発した解析エンジンにより、混雑に関する発言を解析・集計することで、美術館がどれくらい混雑しているのかビジュアル化することに成功しました。このサービスは2013年に公開して以降、様々なメディアで反響を呼び、多くの美術ユーザーのライフスタイルに影響を及ぼしました。現在に至っては年間100万PV以上、利用ユーザー数50万人以上を誇る混雑情報インフラとして利用されています。
混んでる展覧会は満足度半減
美術館は、非日常を満喫するにはもってこいの場所です。しかし、混んでいる美術館で非日常を満喫できるでしょうか? 不可能です。それは美術館ではなく通勤ラッシュの満員電車だからです。運悪く人混みに飲み込まれようものなら、満足度は半減し、あなたの記憶には作品ではなく ”混んでいたこと” のみが強く刻まれることでしょう。
この問題を解決するには、ビッグデータによる集合知を利用するのが最も有効だと考えました。一人だけでは力不足ですが、みんなの発言が結集した時、これまでになかった新たな価値が生まれるはずです。 誰もが快適に美術鑑賞できる世界を作りたい。それが私の願いです。
世界で唯一の高精度混雑エンジン
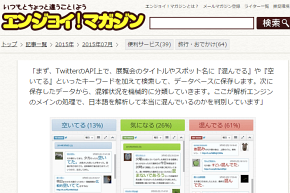
「あの展覧会混んでる?」では最新の混雑状況を皆様にお伝えするために、hanachan が独自に開発した混雑エンジンが活躍しています。この混雑エンジンは、ネット上に散らばる情報を収集し、混雑情報だけを取り出して、混雑度を算出します。日本語の解析には、自然言語処理技術を使用しており、形態素解析や係り受け解析によって複雑な文章に順次対応させています。
2016年1月現在、混雑エンジンは250万ツイートを分析し、7万ツイートを混雑ツイートとして抽出しました。この抽出アルゴリズムの結果はフィードバックされ、hanachan の手によって常に改良されています。
メディア
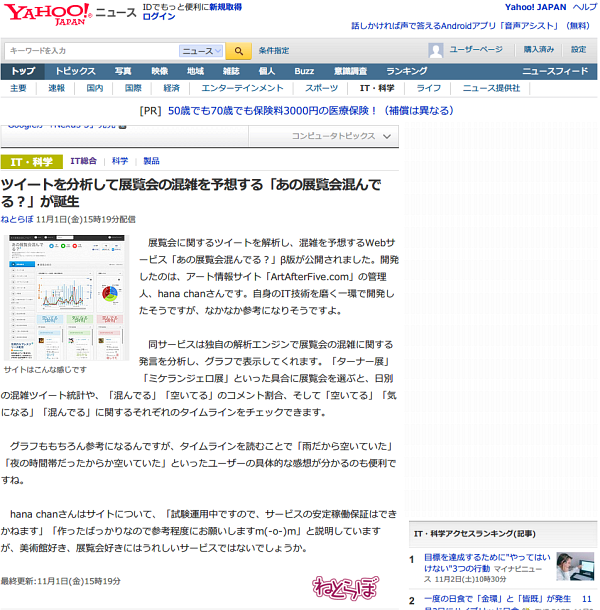


「あの展覧会混んでる?」の機能はティザーサイトで詳しく紹介しておりますのでそちらを参照してください。